Overview about Recommendation systems
On the Internet is a lot of data (films/books/items/email). Almost nobody like to rummaging through the vast amount of things to find an interesting book or an unseen film, which I will like. For this purpose there is a huge development in recommendation systems. In this post I would like to provide a quick overview about this interesting topic.
We need to distinguish:
- between several views of getting data:
- Explicit data
- Implicit data
- between several views of dealing with data:
- Content-based filtering
- Collaborative-based filtering
- User-based
- Item-based
- Knowledge-based filtering
- between several views of loading data
- Model-based (HMP, LDA, Bayesian network)
- Memory-based
- between several way to make prediction
- passive
- active
Explicit data
The user has to take an explicit action - rate a film, write feedback…
Implicit data
The user usually has no idea about it. Browse pages, see a film. There is a problem with interpretation - why he saw that film and not another? It is because he does not like the other one or just did not see it.
Content-bases filtering
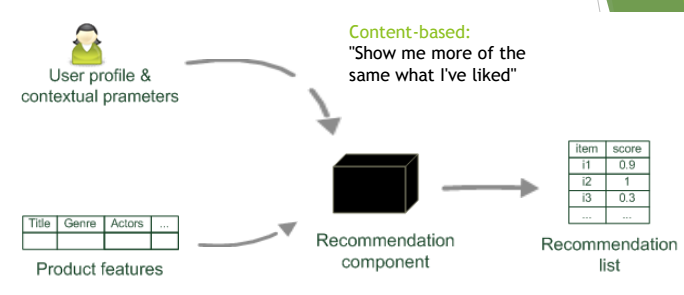
This method is very crucial preprocessing. We need to label our data - for example: this film is about nature and this about startups. We can develop machine learning models to do it instead of human, but it requires time and additional work. Then we recommend items with similar (several metrics) content.
Collaborative-based filtering
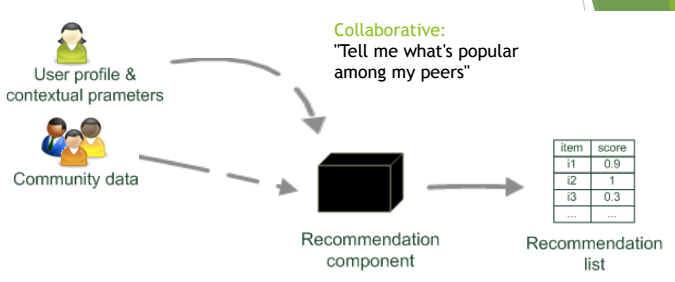
User-based filtering
We exploit information from other users. We find similar users based on their previous ratings and then recommend you what the other think is good and you haven’t seen it yet.
Item-based filtering
We exploit information from other users. We find similar items according user’s ratings and recommend what is most similar to current item and yet not rated by current user.
Knowledge-based filtering
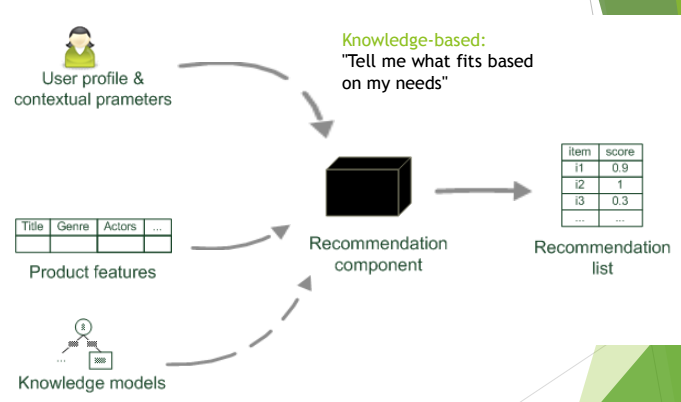
The additional information will be taken from demographics/religious/gender/age/family-size knowledge. Or user have to specify requirements
Model-based
Involve building a model - the model extracts some features from our dataset and use this information/features to predict next recommendation without haven’t to load/use/iterate through a complete dataset. We can think about this as something different from User-based and Item-based.
- Scalability, speed in the prediction
- Speed in adding new data (need to recompute model)
Memory-based
Classical way, where we need to iterate through a complete dataset to find similar user/items. (see. User-based and Item-based)
Passive filtering
Use raw user’s ratings without history to make recommendation. This approach will show the same recommendation for every user.
Active filtering
Use raw user’s ratings with history to make recommendation. This means that the system tries to recommend items which are more similar to them which user has already seen.
In this system, as almost in everything, is the possibility of attacks to prioritize our items or penalize rival’s items. We can defend our system with rules, train model to detect it, use hidden fields and so on.
Hybrid system
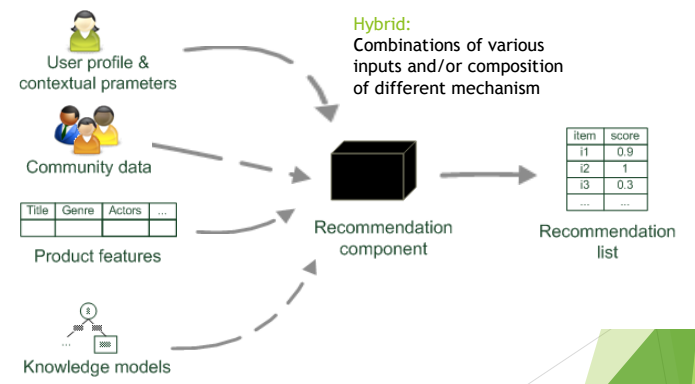
Images was taken from presentation of Dietmar Jannach (presented at RecSys 2017)